
Finding Suggested Movies with Web-Scraping
In this blog post, I’m going to be making a super useful web scraper using scrapy. We will be scraping the IMDB website to find movies and TV shows starring actors from our favorite film/TV shows. In my case, I chose Star Trek: Deep Space Nine. Here’s a link to my project repository.
Here’s how we set up the project:
First, locate the imdb page of your favorite movie or TV show. Here’s the one for Deep Space Nine:
https://www.imdb.com/title/tt0106145/
Now, to initialize the project, open a terminal on your laptop, and type:
conda activate PIC16B
scrapy startproject IMDB_scraper
cd IMDB_scraper
Now that we have our scraper project set up, we can write our scraper functions. Create a file inside the spiders directory (in your IMDB_scraper directory) called imdb_spider.py. Add the following lines to the file:
import scrapy
class ImdbSpider(scrapy.Spider):
name = 'imdb_spider'
start_urls = ['your_start_url']
Next, write your functions.
We will implement three functions, parse( ), parse_full_credits( ), and parse_actor_page( ).
Here’s the implementation of the parse( ) function:
def parse(self, response):
'''
Parses the imdb page of a given movie/tv show,
returning a parse request for the "Full cast & crew" page for
further scraping via the parse_full_credits function
'''
cast_crew_page = "fullcredits"
#cast_link = response.css("a[href*='fullcredits']"::attr(href)")
cast_url = response.urljoin(cast_crew_page)
yield scrapy.Request(cast_url, callback = self.parse_full_credits)
This method works by first accessing our given starting url for our movie/show, and identifies the url associated with the full credits . It then feeds this url to the parse_full_credits( ) function, which will then access every actor that is listed under our given movie/tv show, like this:
def parse_full_credits(self, response):
'''
Parses the imdb full credits page of a given movie/tv show,
returning a parse request for each actor listed for the given movie/show,
for further scraping via the parse_actor_page function
'''
cast_list = [a.attrib["href"] for a in response.css("td.primary_photo a")]
for actor in cast_list:
actor_url = "https://www.imdb.com" + actor
yield scrapy.Request(actor_url, callback = self.parse_actor_page)
Here, we start from the full credits page, and create a list “cast_list” which accesses the url associated with every cast member for our TV show. The attribute “href” identifies the url for the cast memeber. This is equivalent to clicking on each actor’s headshot when navigating the website. Next, for each actor’s url, we pass a further scrapy request to our parse_actor_page( ) function. Here’s it’s implementation:
def parse_actor_page(self, response):
'''
Parses the imdb page of a given actor,
returning a dictionary for each movie/TV show they starred in,
containing the actor's name and the movie/show
'''
actor_name = response.css("h1.header span.itemprop::text").get()
for movie in response.css("div.filmo-row"):
if "actor" in movie.css("::attr(id)").get():
yield {
"actor" : actor_name,
"movie_or_TV_name" : movie.css("a::text").get()
}
To write this function, we first identify the text in the header of the actor’s imdb page which provides their name. You can find this using the inspect function in your Developer Tools on your browser. Then for each movie or show listed on the site, we check that they are listed as an actor, and we yield a dictionary containing their name, and the name of the movie or show.
Finally, we can run:
scrapy crawl imdb_spider -o results.csv
to create a .csv file with a column for actors and a column for movies or TV shows.
With this, we can then create all sorts of visualizations to compare the shows and movies associated with our favorite production.
Visualizing our Results
Let’s load our results, and use them to generate a sorted list to identify the movies and TV shows that share the most actors with Star Trek: Deep Space Nine.
import pandas as pd
import numpy as np
movies = pd.read_csv("/Users/romankouznetsov/Documents/web_scraping/IMDB_scraper/IMDB_scraper/movies.csv")
#Create a Pandas dataframe with all movies sorted by the number of actors from which we scraped,
#i.e. the actors that appeared in Star Trek: DS9
counts = movies['movie_or_TV_name'].value_counts()
movie_rankings = pd.DataFrame(data = {'movie': counts.keys(), 'number of shared actors': counts})
movie_rankings

Now we can visualize these results using plotly! Let’s generate a histogram for the movies that share the most actors with DS9.
import plotly.express as px
fig = px.histogram(data_frame = movie_rankings[1:20],
x = "movie",
y = "number of shared actors",
title = "Top 20 movies that share the most actors with Star Trek: Deep Space Nine")
fig.show()
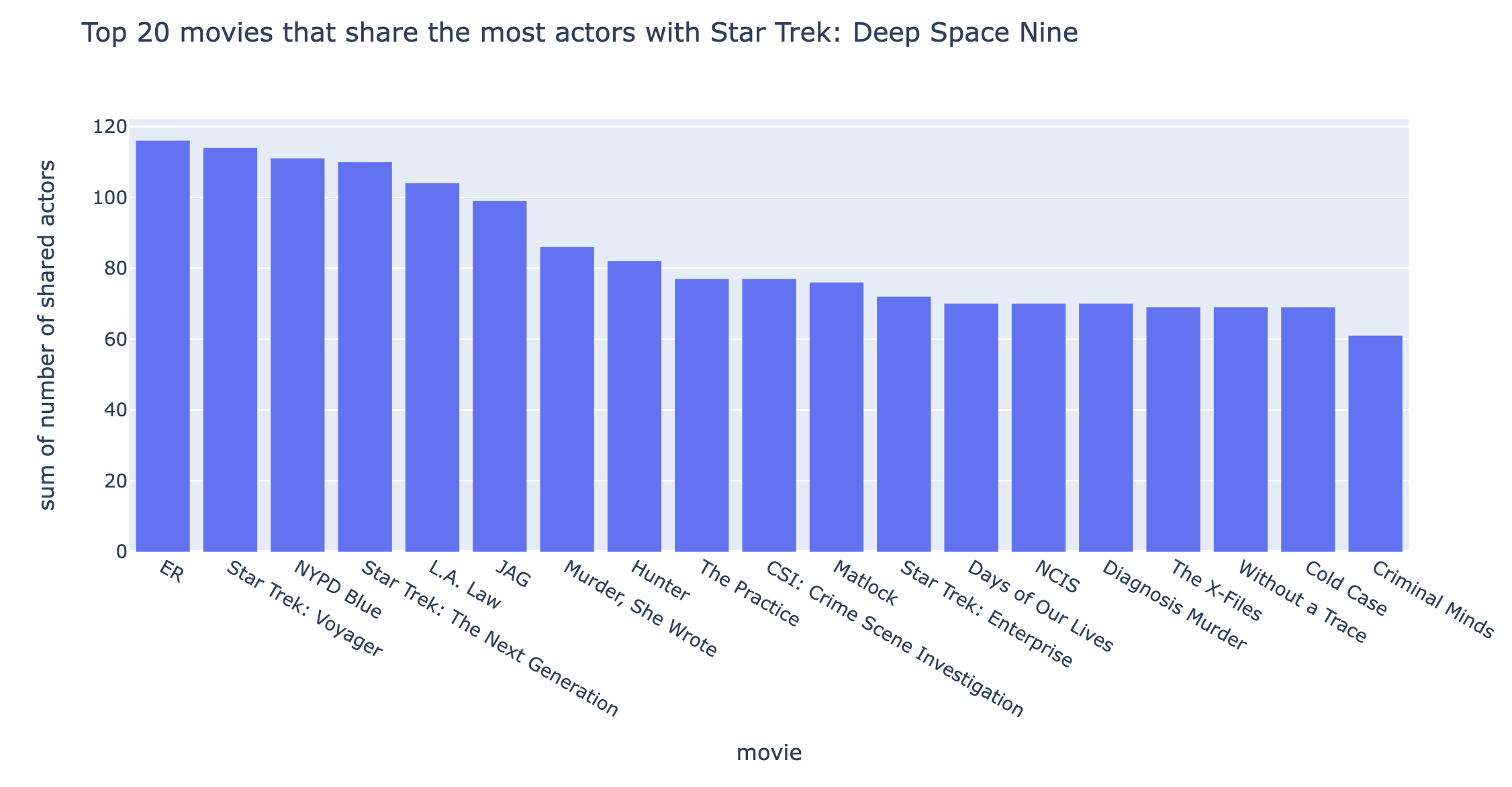
There we have it, thanks to webscraping, we can fins shows related to our favorites. We now have our own “Suggested to Watch” algorithm, albeit a simple one.